

What if we contributed to Wikipedia instead of publishing papers?
What if we contributed to Wikipedia instead of publishing papers?
An unhinged take on academic publishing.

Over the last few years, I have witnessed a number of twitter hot-takes, reddit debates, and more serious essays on the pitfalls of academic publishing.
It promotes bad science by enforcing the publish or perish mantra, they say!
It’s too biased, they say!
It’s too expensive, they say! Well, I say...
On the other hand, the aim of peer reviewed academic publishing is to ensure that what does get published is of sufficient quality to be useful to the scientific community and hopefully to the broader public. I hope that we got into science because we hoped we could make a difference in the world. If you got into science because you thought it would make you an attractive partner choice, everyone loves science until you go on a 30 minutes rant about how you can create logic gates in Connway’s game of life using gliders and that if you can create logic gates, you can create computer programs and so you can encode the game of life within the game of life! Can you imagine that? The multiple levels of emergent properties is just crazy. It’s just four basic rules you know? Just four!
I digress.
If you got into science “for the money”, I have bad news for you…
I digress again.
Not to sound unhinged but:
What if we contributed to Wikipedia instead of publishing papers?
Journal papers are built on an antiquated knowledge structure
Scientific curiosity and discussion has been around for thousands of years but the formal sharing of ideas in the form of a scientific publication in an academic journal is roughly 350 years old. At the time, less than a dozen journals existed. Now? Over 100 000. Asghar Ghasemi et al. summarizes the history of scientific publication in biomedical research.
More importantly for this unhinged argument, scientific publications still to this day follow a variation of a format that made sense in the era of paper journals: an end to end story starting with an abstract, an introduction, some results, a little discussion, more or less depth in the methods used, and finally citing the work of others.
Now, Reader, be honest. How many times do you actually read the whole paper from start to finish? Do you really have the time to do that for all those papers you want to read? You probably have so many tabs opens to “papers-to-read” that you get lost trying to find which tab is playing music. I know I do. Once a month, I move those papers to a dedicated Notion page and then still not read them but at least I know where the music comes from.
If you are somewhat familiar with the field, you will skip most of the introduction, since the authors will contextualize their work using similar story flows and citations. You will probably skip over the methods that are not relevant to your work. Knowing the primer sequences used in a PCR experiment is important to some, but for a computational biologist, it is mostly irrelevant. You might even disregard result sections since they are not relevant for you either. We write papers in the form of compelling stories because publishing in a physical journal requires a “whole package” to be comprehensible. A journal such as Nature will have papers across many fields and we - as readers - we need the research to be nicely packaged and contextualized for it to make sense. We need that introduction to give us context. We need those results to know what has actually been discovered. We need those method to know how it was discovered and maybe to reuse the same methods in our own work. We need to read that discussion to see what it could mean for the field and maybe some of the limitations the authors have identified.
It follows that new knowledge is fairly sparse in any given paper. We validate our findings using multiple experiments and techniques. We benchmark our models against other models and compare their performance - just like all the other models did. We demonstrate that our new method works by recovering already known information just so we can say: “look! I told you it works!”
I really don’t want to sound unhinged but:
The majority of a paper is there to support the story and not to provide new knowledge.
While this made sense in the world of physical journals, in an increasingly digital world, I am not convinced that this format is still the most appropriate to present the outcomes of the scientific method.
Don’t get me started on how antiquated the current view of the scientific method is. That will be for another unhinged rant.
Leveraging Knowledge Graphs and continuous knowledge updates.
The hyperlinks in Wikipedia pages have spawned a game called Wikipedia speed runs where the goal is to get from a start page to an end page as quickly as possible only using hyperlinks. This demonstrates that the information contained on the website is structured as a graph and can be navigated by jumping between nodes. Some have even create nice graph visualizations of Wikipedia content. Wikipedia also organizes its articles hierarchically with their portals and summary pages. Each pages summarizes and provides links to pages contain within its scope.
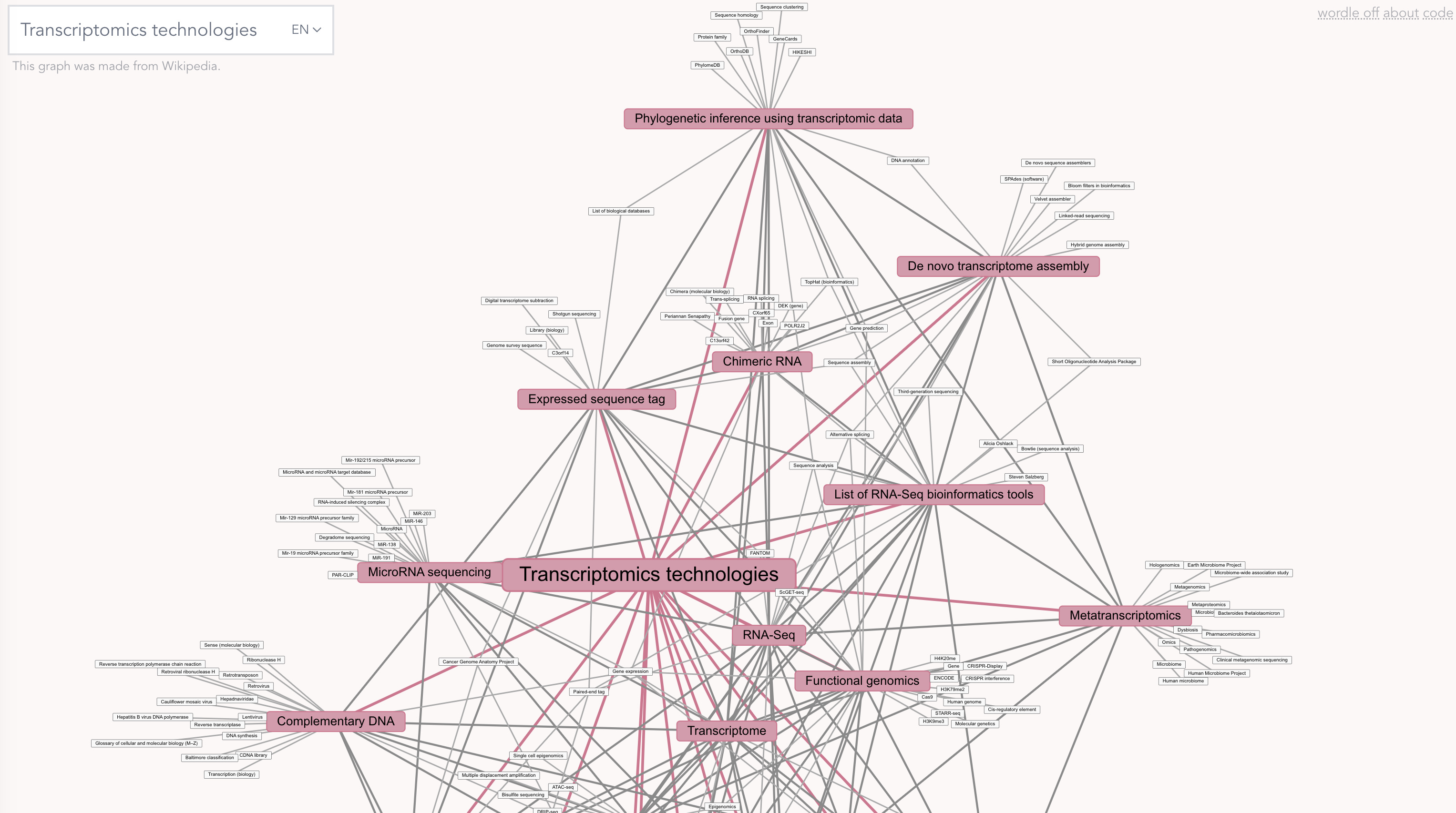
Let’s go through the following path and see what we get:
Science portal ⇒biology portal ⇒ Gene expression page ⇒ messenger RNA
The messenger RNA page contains an overview of our knowledge on messenger RNA linking towards relevant academic papers. One example is the mention of increased levels of EEF1A1 proteins in breast cancer in conjunction with lover levels of EEF1A1 mRNA.
Obviously, the concept of knowledge graphs has been around for decades but what is less obvious is why we are not leveraging this concept more seriously in academic publishing?
The results of any given experiment can be mentioned in the relevant articles and the supporting data can be its own page with raw data and code (when relevant) highlighting how this very specific result was obtained. The need for big and bold stories with dozens of experiments become less relevant. We would contribute to the knowledge graph instead of writing stand alone papers. The knowledge can be directly linked to all other instances and pages where it could be useful and relevant. The higher order pages that serve as a summary of a field become continuously updating review papers and meta analyses. The impact of research and protocols will be highlighted by their node connectivity. All the redundant data that was required to write a self-contained story is not required. At least not directly and is collaboratively provided by all other researchers in the field.
As a computational biologist often working with spatial-omics data, I have read dozens of spatial-omics tools which often use the same data sets and the same other methods to benchmark their performance. In this instance, benchmarking data sets would be hosted on a dedicated page to which developers can publish the performance of their method on a leader board. This approach has already being used in the Machine Learning world with excellent initiatives such as papers-with-code.
No more installing dozens of tools! No more testing an optimizing tools to compare performance! Benchmarking becomes a continuous process where developers can opt to test their tool on a variety of data sets and if new data sets become available they can try their approach on the new data an update their results.
You found a way to optimize the code which boosts performance? No worries, re-run the new approach on the benchmarking data and show the work almost immediately instead of finding a way to write this optimization as a stand alone paper which might get stuck in an eternal loop of rejection until you decide to give up.
For multi-task tools, the same process can be applied across tasks. And if you have a completely new task? Well, you can either provide new high quality data sets or re-use publicly available data sets and simply create a new task page.
Equitable scientific contributions and peer-review
I can already hear the cries of protest: Wikipedia is not a reliable source of information and knowledge! Anyone can contribute and modify pages. Yes, everyone can contribute and modify pages. And that is the whole point. The paradigm proposed here requires a drastic shift in the way we approach science and research.
First, we would need to recognize that a scientific contribution can be as simple as a high-school level experiment. It could be as small as changing a few lines of code boosting the performance of an algorithm. These small contributions should be valued for their own merit.
Second, it is all too common for those lucky enough to be part of large well funded labs to ride the coattails of large impactful papers with little to no actual contribution. They will reap the benefits of having highly cited papers to their name and the clout associated with the big names in a field. In addition, high impact journals disproportionally publish work from the US and Europe leaving scientist from other parts of the world and less well funded labs struggling to get their contribution to mankind’s knowledge recognized. And this, even if their research is actually robust and useful.
Third, the scientific value of a contribution would be assessed in a similar context for everyone. A researcher performing a knock-down experiment of a specific gene will be evaluated on the quality of that specific experiment and not on the broader story of a paper. Results wouldn’t have to be positive or hypothesis confirming to be valued. They would simply need to add to our library of knowledge.
Anyone, anywhere, can contribute to the sum total of humanity’s knowledge. And yes, even non-academics. This means that the questionable theories provided by your drunk uncle at a family dinner will be given the same consideration as more robust and serious research work. Both contributions will be peer-reviewed and discussed before being accepted for the merit they hold. The focus or peer-review will shift towards assessing the strength and weaknesses of specific and narrow contributions rather the broader narrative in which they are presented. It means that anyone can contribute and receive peer-review for their ideas - even your drunk uncle. Hopefully, the drunk theories will remain an entertaining topic of family discussion. This process is already applied to any Wikipedia modifications. There is a discussion board for each page where the page’s organization and the veracity of facts presented are openly discussed.
A parallel can be made with GitHub pull requests. When someone makes a contribution to an open-source project, a pull request is made and reviewed. It is openly discussed and modified until it is agreed that the changes can and should be merged with the rest of the repository. In our context, every topic can have a set of reviewers that will assess new contributions based on the robustness of the experimental protocol/design or the strength of the analysis.
This would also give the opportunity to junior researchers to more actively participate in the review process. Let’s be honest, having an undergrad student who runs 300 PCR runs a week might be better at assessing another PCR experiment than a PI who hasn’t set foot in a lab in the last decade. Conversely, this PI would be much better at assessing the broader scope of research and how summary pages should be organize to best reflect the state of our knowledge. But most importantly, anyone at any level can participate in the discussion and review process. Non scientists can read the discussion and ask questions spurring us to clarify what we are doing and why. The public funds our research. Let us all have the opportunity to witness and be involved in the process.
When applying for career advancements, one could pull down their contribution list from wikipedia highlighting what they have done over the last few years. Contributions could be categorized such as “New data set”, “Analysis”, or “Summary page” to show the specific tasks accomplished over the years. It would also be possible to see how specialized or interdisciplinary someones research has been based on how wide their contribution network is. You could even just have a visual graph as CV instead of pages and pages of dry text.
And for those worried about impact, summary pages for a broad topic will summarize knowledge from more specific pages that will utilize the data produced at the level of individual contribution pages. How far up the chain your work goes defines the impact of your work. Even the most modest contribution can have a high impact. And for those who have responsibilities outside of science and research, it could help them to remain competitive in the eyes of hiring and promoting committees. (”Why did you only published one paper in the last 2 years?” - “You had a child? How is that relevant?” - “Oh you had some health issues? Sound to me like you are not dedicated enough.”)
We could imagine that this new approach can generate new careers in academic research: Keepers of the Graph. Those who organized, link, curated, write, and clean every page available. Specialists in organizing information and providing the best experience to access and interact with the data and knowledge, we, as a scientific community, have generated.
Wikipedia exists in multiple languages and with the advent of Large Language Models and high quality translators, the sum total of our knowledge could be accessible in any language while still linking to the same raw data. Educational science pages could be created where student interact with real-world data. Ultimately, this approach could reduce the barrier to entry to science and science education.
Identifying Gaps in Knowledge
Wikipedia has had the sense to remove it, but there was a time where Wikipedia would indicate: “This list is incomplete. You can help by expanding it” at the top of pages related to mass shootings. This might not be the gap in knowledge you should look into contributing to. If you are a regular Wikipedia user, you will have noticed that some hyperlinks are red and not blue indicating that the page does not yet exist. Currently, we indicate the gap in knowledge in our introductory paragraphs and how we plan to fill it. In a Wikipedia like setting, missing knowledge can be shown as these empty pages or pages that need to be expanded.
In parallel to summary pages, knowledge gap pages would catalog where research is required. At a large scale, it would help us to organize the big questions in an open and transparent way where anyone can jump in and expand on a topic. Researchers from around the world can easily see what needs to be done and pledge to carry out an experiment or run some analysis, even if these small experiments don’t fit the broader narrative of a paper or lab. Maybe, you ran a sequencing experiment looking at the binding a specific protein and you noticed that that same experiment would be required somewhere else. Boom - link the data in the graph. You have that plasmid and those primers for that specific gene? You can run that validation experiment while waiting for another experiment to finish. Boom - link the data in the graph.
What if more than one person decides to contribute to the same topic? All the better! The research community has often decried the lack of reproducibility and replicability of many scientific publications. Multiple labs contributing to the same questions and experiments would either show similar results in which case the findings are indeed reproducible or they would show conflicting results in which case a vibrant discussion on how to improve things can be had. Since this paradigm would favor contributions over papers, there would be no penalty to scientist who reproduce results. In fact, it would encourage it.
From an educational perspective, we could imagine large classes of high school or undergraduate students selecting some of these missing knowledge pages as a school project. Think of all the genes that are understudied because they don’t fit the current hype of the field. More often than not, we are dissuaded to study their function since it would be a risky career move if it doesn’t lead to a good story and paper. These genes would have thousands of minds working towards elucidating their function and their role. It could inspire thousands to participate in the research effort as they would effectively and visibly be advancing human knowledge.
It’s not all roses
To paraphrase Gary Kasparov, I remain an optimist because I don’t see much utility in pessimism. And yet, I should not pretend like this is the perfect solution to all our woes.
While a system of individual contribution is aimed to smash the barrier to entry to scientific research and reduce bias, it is also a system that can be abused and could favor certain fields over others. Computational work would have an edge over experimental work since it does not require as much time nor resources to produce results. It is also much easier to commit dozens of small contributions a day which would be impossible for wet lab scientists. When your experiment takes 3 days to run and there is no guarantee that it will actually work, you will not be able compete in number of contributions with someone who can change a few lines of code here and there. An option is providing weighted contributions or at least provide a clear categorization indicating effort and resources require for the production of new results.
We should not overlook the fact such a system will require each individual scientists to contribute their own work. Depending on the personality of the PI, this could become problematic. We have all heard to horror stories of toxic leaders micro-managing every aspect of the work. It is likely that their malicious and self-serving intent would hoard data and submit new results in their name.
Wikipedia is free to use and lives off donations. If we were to actively use it in this context, it would require substantial financial and technical expansion. The exponentially growing number of pages and the associated data will need to be stored and accessible at scale. New standards of data accession would need to be implemented to easily utilized the data that is available. It also begs the question of how do we handle confidential data. The confidential nature of clinical data , for instance, would be at odds with the fully transparent open source ethos of wikipedia. Advances in distributed learning models (Swarm learning) or better encryption could potentially provide a way to access the knowledge hidden with the data without putting in jeopardy the privacy of participants. As for the financial aspect, we already seem to be willing to pay thousands of dollars to publish in high impact journals. Why not give it to wikipedia?
Ironically, this process could also slow down scientific progress. Since every individual contribution needs to be assessed before being merged into the main pages, the work load for reviewers might increase drastically. No more skimming through the main ideas of a paper before taking a publication decision! We would need to actually look at every aspect of the work in detail. Hopefully, this might reduce the number of phallically gifted rats being published. Thankfully, every review could be cut into smaller manageable chunks that might only take a few minutes to assess. Reviews could also count as contribution to scientific knowledge. It might even spawn new career options as professional reviewers or curators of knowledge.
The whole process of carrying out research would need to change and this change might be a hard pill to swallow. Papers provide a clear context container to select and organize experiments and analysis. Here, the broader context of work carried out in a lab would be less clear. It would need to account for many moving parts and constant changes in our knowledge base. How do we organize our research questions and interests in a fast moving and ever evolving landscape? Furthermore, how would this work with the current mode funding research which is also built on the “packaged story line” approach? The visibility of the rate of change can be overwhelming and might not clearly fit with the rest of the industry. With that said, the packaging of information for scientific dissemination does not bar us from thinking in terms of narrative to direct the efforts of our lab. It simply opens the door for different ways of constructing scientific narrative and contribution.
It will also require us - as individuals - to accept that the glory of papers is nice but ultimately futile. We all aim (I hope) to improve the human condition through our research: From understanding the nature of the cosmos giving us a better sense of what is the nature of this whole mess we call reality, to finding new therapies to help our loved ones live healthy lives and fend of grief a little longer. These advancements is what should really matter. Not the big papers. Not those big citation numbers. Sadly, I have met some researchers who would despise this idea with a burning passion. How could one intellectually peacock when their work would be consider as equal in merit to some high school kid messing around in their basement? This change in mindset can and will lead to better outcomes for everyone. The concept is brilliantly discussed and argued by Simon Sinek in his book The Infinite Game.
Finally, there is the question of Large Language Models. If we only consider the aspect of data summary and creation of useful knowledge graphs, then surely it would be much easier to just train these new and constantly improving models on the sum total of scientific literature. The integration of LLMs and knowledge graphs is a vibrant field of research and promises to deliver many useful tools and insight into our current state of understanding of the world. LLMs still have their limitations and the veracity of the text generated is often questionable. By committing our work to the graph, we might more effectively provide a high quality and easy(ish) data set to train these models. As for the models that already exists, we can use them to convert papers to Wikipedia like articles with relevant links. Centuries of research can be re-organized to support the graph. We might see the emergence of effective AI research partners that can link useful pages and data sets, maybe even providing novel research ideas.
What we owe humanity
Overall, I believe this concept has at least some merit. There is no doubt that it also has many pitfalls. But I believe that this approach will hit at the heart of what should be the most important to us and is too often forgotten: our humanity. We should encourage and promote a system that puts humanity at the forefront of our mind.
Yes - this brings research to the level of the individual - reducing instead increasing the scale of single contributions. It does not mean the end of labs and large collaborative groups. The Large Hadron Collider would certainly not be possible without massive efforts across boarders and labs. Labs, departments, and institutes would still have their place. They would provide shared resources to more effectively carry out the big hard experiments. It will serve as a way to enhance information dissemination.
As researchers, we are at the service of humanity. The inclusion of all peoples in the process is necessary for useful and impactful research. I like to believe that if more people felt included in the effort, we would more effectively move forward. Progress for the sake of progress, progress that forgets who it serves is simply not worth it. There is an argument to be made about how this lack of inclusion in the effort is why so many have lost trust in the sciences. It could explain the growing resistance to scientific endeavors in favor of social endeavors. We may have forgotten that science is first and foremost a social endeavor. We may not like to have to contend with some of the more challenging views (I know I did when I met a real life flat-earther - I thought it was an internet meme) but they are also part of humanity. And we serve them as well. All of them.
I, for one, will start organizing and summarizing the knowledge of my field into Wikipedia pages and perhaps add my own scientific contributions.
Not to sound unhinged but…
I am researcher in bioinformatics. I started off as a Molecular biologist who realized that computational biology and bioinformatics was way more fun and safe. I am what is commonly referred to as “pretty clumsy” to the point where I would probably have my own lab safety hazard training section. To quote a friend when I once trip and fell on a flat beach: “How on earth did you manage to survive this long?”.
Non-Fiction & Fiction
This is a place for me to explore my love for writing and discuss topics such as science, philosophy, history, society, or which ever thought consumed my mind at the time.
I will also write short sci-fi short stories based on real and recent research. Science fiction has the ability to inspire. It has the ability to marvel at what researchers have already accomplished.
My writing will remain free since I am a big proponent of open-source and free access to knowledge - yes I use that term very lightly here. Sadly, I can only write when I have the time and so, essays and short stories will be fairly sparse to begin with.
Interesting post. I do encourage academics to get involved in editing Wikipedia, if they're so inclined, but besides being prepared to deal with numerous conflicts they might not expect to have, they should be aware that Wikipedia is very explicitly scoped to be *not* for publishing original research. (This is a longstanding rule that's been subject to a lot of wrangling; see https://en.wikipedia.org/wiki/Wikipedia:No_original_research for a summary of the consensus.) Rather than try to fight Wikipedians on that, I'd encourage academics instead to find other suitable venues for publishing that research. (There's a wide variety of venues beyond the usual suspects, and more are emerging all the time.) If that research is published in a peer-reviewed venue that Wikipedians find trustworthy, it can be then be summarized and cited in appropriate relevant Wikipedia articles.
I am not a scientist, but I have always felt that the research journals which have paywalls to prevent the public from reading the studies is very unscientific. Journalists get the research results, although I have no idea if this comes from PR hype about studies or whether the journalists actually get to read the studies and report on them. If not Wikipedia, why not the BMJ. Or even scientists publshing research studies on Substack—but preventing Substack from paywalling the posts.